Understanding Residue Attributes in Molecular Modeling
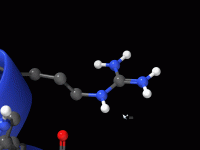
Residues are fundamental building blocks in molecular models, whether you’re working on proteins, DNA, RNA, or similar structures. However, understanding how to efficiently manage, analyze, and interact with residues can sometimes feel overwhelming. With SAMSON’s Node Specification Language (NSL), this…